learning, hyperparameter optimization or tuning is the problem of choosing a set of optimal hyperparameters for a learning algorithm. A hyperparameter is a...
24 KB (2,493 words) - 06:24, 9 October 2024
instead apply concepts from derivative-free optimization or black box optimization. Apart from tuning hyperparameters, machine learning involves storing and...
10 KB (1,139 words) - 17:09, 30 September 2024
Bayesian optimization is a sequential design strategy for global optimization of black-box functions, that does not assume any functional forms. It is...
16 KB (1,686 words) - 06:17, 9 October 2024
(without constructing and training it). NAS is closely related to hyperparameter optimization and meta-learning and is a subfield of automated machine learning...
26 KB (2,980 words) - 06:35, 9 October 2024
hand-designed models. Common techniques used in AutoML include hyperparameter optimization, meta-learning and neural architecture search. In a typical machine...
9 KB (1,031 words) - 06:28, 9 October 2024
Learning rate (category Optimization algorithms and methods)
into deep learning libraries such as Keras. Hyperparameter (machine learning) Hyperparameter optimization Stochastic gradient descent Variable metric...
9 KB (1,108 words) - 10:15, 30 April 2024
forgetting Continual learning Domain adaptation Foundation model Hyperparameter optimization Overfitting Quinn, Joanne (2020). Dive into deep learning: tools...
13 KB (1,370 words) - 16:00, 16 September 2024
Proximal policy optimization (PPO) is an algorithm in the field of reinforcement learning that trains a computer agent's decision function to accomplish...
15 KB (2,048 words) - 04:23, 7 October 2024

Genetic algorithm (redirect from Optimization using genetic algorithms)
GA applications include optimizing decision trees for better performance, solving sudoku puzzles, hyperparameter optimization, and causal inference. In...
68 KB (8,038 words) - 11:58, 29 September 2024
preserved. CUR matrix approximation Data transformation (statistics) Hyperparameter optimization Information gain in decision trees Johnson–Lindenstrauss lemma...
21 KB (2,248 words) - 01:18, 10 September 2024
function, a grid-search algorithm can be utilized to automate hyperparameter optimization [citation needed]. A way of testing sentence encodings is to...
9 KB (980 words) - 14:31, 16 July 2024
optimization under uncertainty. In machine learning, algorithmic approaches to model selection include feature selection, hyperparameter optimization...
21 KB (2,276 words) - 18:21, 2 October 2024
that are not parallelized within scikit-learn and Incremental Hyperparameter Optimization for scaling hyper-parameter search and parallelized estimators...
32 KB (3,043 words) - 23:26, 29 August 2024
Selection and Hyperparameter optimization (CASH) problem, that extends both the Algorithm selection problem and the Hyperparameter optimization problem, by...
6 KB (535 words) - 02:58, 28 August 2024

by using another overlaying optimizer, a concept known as meta-optimization, or even fine-tuned during the optimization, e.g., by means of fuzzy logic...
48 KB (5,077 words) - 23:59, 2 July 2024
good k can be selected by various heuristic techniques (see hyperparameter optimization). The special case where the class is predicted to be the class...
31 KB (4,251 words) - 12:27, 4 October 2024
Leyton-Brown, Kevin (2013-08-11). Auto-WEKA: combined selection and hyperparameter optimization of classification algorithms. Proceedings of the 19th ACM SIGKDD...
11 KB (1,050 words) - 03:40, 14 August 2024
Sequential minimal optimization (SMO) is an algorithm for solving the quadratic programming (QP) problem that arises during the training of support-vector...
7 KB (1,009 words) - 19:30, 1 July 2023

precision Bias of an estimator Double descent Gauss–Markov theorem Hyperparameter optimization Law of total variance Minimum-variance unbiased estimator Model...
28 KB (3,895 words) - 14:42, 11 October 2024
Probabilistic numerics (section Optimization)
J. R. (2022). Preconditioning for Scalable Gaussian Process Hyperparameter Optimization. International Conference on Machine Learning (ICML). arXiv:2107...
39 KB (4,266 words) - 17:56, 13 May 2024
Multi-task optimization is a paradigm in the optimization literature that focuses on solving multiple self-contained tasks simultaneously. The paradigm...
12 KB (1,307 words) - 21:09, 8 August 2024
PMID 36930210. Yang, Li; Shami, Abdallah (2020-11-20). "On hyperparameter optimization of machine learning algorithms: Theory and practice". Neurocomputing...
16 KB (1,749 words) - 04:16, 19 August 2024
ISBN 9789461970442. Soper, Daniel S. (2021). "Greed Is Good: Rapid Hyperparameter Optimization and Model Selection Using Greedy k-Fold Cross Validation" (PDF)...
42 KB (5,623 words) - 18:40, 25 June 2024
processes are popular surrogate models in Bayesian optimization used to do hyperparameter optimization. A genetic algorithm (GA) is a search algorithm and...
134 KB (14,766 words) - 10:49, 19 October 2024
Hyperparameter optimization Model selection Relief (feature selection) Sarangi, Susanta; Sahidullah, Md; Saha, Goutam (September 2020). "Optimization...
58 KB (6,933 words) - 03:15, 11 March 2024
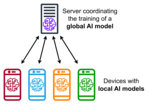
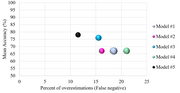
authors also introduce a hyperparameter selection framework for FL with competing metrics using ideas from multiobjective optimization. There is only one other...
50 KB (5,762 words) - 05:50, 25 September 2024
settable online learning progress report + auditing of the model Hyperparameter optimization Vowpal wabbit has been used to learn a tera-feature (1012) data-set...
5 KB (406 words) - 11:13, 13 September 2024
minimization Entropy maximization Highly optimized tolerance Hyperparameter optimization Inventory control problem Newsvendor model Extended newsvendor...
70 KB (8,336 words) - 05:14, 24 June 2024
Hippo, a protein kinase involved in the Hippo signaling pathway Hyperparameter optimization, a technique used in automated machine learning This disambiguation...
754 bytes (121 words) - 19:19, 28 July 2022

separable pattern classes. Subsequent developments in hardware and hyperparameter tunings have made end-to-end stochastic gradient descent the currently...
159 KB (16,821 words) - 16:20, 19 October 2024