Batch normalization (also known as batch norm) is a method used to make training of artificial neural networks faster and more stable through normalization...
29 KB (5,791 words) - 21:22, 25 December 2024
learning, normalization is a statistical technique with various applications. There are two main forms of normalization, namely data normalization and activation...
32 KB (4,752 words) - 19:11, 6 December 2024
method used to normalize the range of independent variables or features of data. In data processing, it is also known as data normalization and is generally...
8 KB (1,041 words) - 01:18, 24 August 2024
vectors within a ball of radius g m a x {\displaystyle g_{max}} . Batch normalization is a standard method for solving both the exploding and the vanishing...
24 KB (3,728 words) - 18:58, 12 December 2024
famous for proposing batch normalization. It had 13.6 million parameters. It improves on Inception v1 by adding batch normalization, and removing dropout...
10 KB (1,116 words) - 18:52, 5 November 2024
careful weight initialization to decrease the need for normalization, and using normalization to decrease the need for careful weight initialization,...
24 KB (2,860 words) - 16:38, 21 December 2024
top-level Internet domain BN-reactor, a Russian nuclear reactor class Batch normalization, in artificial intelligence Benzyl functional group (Bn), in organic...
2 KB (321 words) - 16:30, 18 November 2024
networks. It supports other common utility layers like dropout, batch normalization, and pooling. Keras allows users to produce deep models on smartphones...
6 KB (518 words) - 10:54, 27 December 2024

updates tend to push weights in one direction (positive or negative). Batch normalization can help address this.[citation needed] ReLU is unbounded. Dying...
17 KB (2,280 words) - 19:13, 6 December 2024
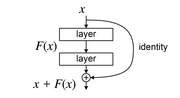
interlaced with activation functions and normalization operations (e.g., batch normalization or layer normalization). As a whole, one of these subnetworks...
26 KB (2,876 words) - 08:01, 29 December 2024
altogether, replaces tanh with the ReLU activation, and applies batch normalization (BN): z t = σ ( BN ( W z x t ) + U z h t − 1 ) h ~ t = ReLU (...
8 KB (1,278 words) - 22:37, 2 January 2025
through using more sophisticated means of doing data normalization, rather than batch normalization. The way the statistical local outputs are pooled and...
51 KB (5,915 words) - 06:23, 18 December 2024
inputs that are zero mean/unit variance. Batch normalization was introduced in a 2015 paper. It is used to normalize the input layer by adjusting and scaling...
270 KB (29,478 words) - 02:48, 26 December 2024

known as YOLO9000) improved upon the original model by incorporating batch normalization, a higher resolution classifier, and using anchor boxes to predict...
10 KB (1,221 words) - 01:17, 19 October 2024
Glass batch calculation or glass batching is used to determine the correct mix of raw materials (batch) for a glass melt. The raw materials mixture for...
7 KB (862 words) - 04:16, 27 January 2021
Here, a 27-layer network is used with multiple convolution layers, batch normalization, and ReLU activations. It uses a standard ADAM optimizer. The CNN...
58 KB (8,126 words) - 09:47, 19 November 2024
convolution, pooling, skip connection, attention, batch normalization, and/or layer normalization. Every setting of a neural network's parameters θ {\displaystyle...
20 KB (2,964 words) - 01:28, 19 April 2024
Softmax function (redirect from Normalized exponential)
that avoid the calculation of the full normalization factor. These include methods that restrict the normalization sum to a sample of outcomes (e.g. Importance...
31 KB (4,761 words) - 23:32, 19 December 2024

Prothrombin time (redirect from International normalized ratio)
tissue factor they manufacture. The ISI value indicates how a particular batch of tissue factor compares to an international reference tissue factor. The...
24 KB (3,092 words) - 19:25, 25 December 2024
Flow-based generative model (redirect from Normalizing flow)
learning that explicitly models a probability distribution by leveraging normalizing flow, which is a statistical method using the change-of-variable law...
26 KB (3,915 words) - 13:57, 12 December 2024
Significand (redirect from Normalized mantissa)
204–205. ISBN 0-89874-318-4. Retrieved 2016-01-03. (NB. At least some batches of this reprint edition were misprints with defective pages 115–146.) Torres...
16 KB (1,673 words) - 18:03, 23 November 2024
steps in the analysis of RNA-seq data is data normalization. DESeq2 employs the "size factor" normalization method, which adjusts for differences in sequencing...
8 KB (605 words) - 14:54, 30 June 2024
other computer processing models, such as batch processing, time-sharing, and real-time processing. Batch processing is execution of a series of programs...
14 KB (1,656 words) - 00:42, 24 August 2024
cleansing can be performed interactively using data wrangling tools, or through batch processing often via scripts or a data quality firewall. After cleansing...
18 KB (2,614 words) - 11:48, 2 December 2024
and considering various normalization methods, the committee arrived at the following formula for calculating the normalized marks, for CE, CS, EC, EE...
75 KB (3,911 words) - 16:17, 30 December 2024

Square Layer Normalization". arXiv:1910.07467 [cs.LG]. Lei Ba, Jimmy; Kiros, Jamie Ryan; Hinton, Geoffrey E. (2016-07-01). "Layer Normalization". arXiv:1607...
47 KB (4,367 words) - 18:36, 1 January 2025

CNN = convolutional layer (with ReLU activation) RN = local response normalization MP = maxpooling FC = fully connected layer (with ReLU activation) Linear...
15 KB (1,550 words) - 22:59, 2 January 2025
groups (known as "batches") of housemates, representing three Kumunities: celebrities, adults and teens. On the fourth and final batch, the top two housemates...
355 KB (10,475 words) - 23:28, 10 December 2024
Chinese people" in different eras also point to different groups. The first batch of "old friends", represented by Edgar Snow and Ma Haide, were foreigners...
9 KB (823 words) - 02:18, 15 October 2024

steps), before decaying again. A 2020 paper found that using layer normalization before (instead of after) multiheaded attention and feedforward layers...
101 KB (12,612 words) - 22:44, 2 January 2025