analysis in the presence of heteroscedasticity, which led to his formulation of the autoregressive conditional heteroscedasticity (ARCH) modeling technique...
27 KB (3,191 words) - 23:32, 30 August 2024
Autoregressive conditional heteroskedasticity (redirect from Autoregressive conditional heteroscedasticity)
Garthoff, R. (2018). "Generalised spatial and spatiotemporal autoregressive conditional heteroscedasticity". Spatial Statistics. 26 (1): 125–145. arXiv:1609...
23 KB (3,820 words) - 19:30, 26 May 2024
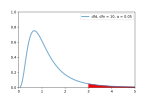
F-test (section Formula and calculation)
Bartlett's test, and the Brown–Forsythe test. However, when any of these tests are conducted to test the underlying assumption of homoscedasticity (i.e. homogeneity...
17 KB (2,179 words) - 08:12, 17 December 2024
Robust regression (section Heteroscedastic errors)
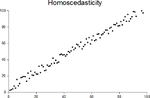
heteroscedasticity. In the homoscedastic model, it is assumed that the variance of the error term is constant for all values of x. Heteroscedasticity...
21 KB (2,643 words) - 18:11, 25 November 2024
exhibit a phenomenon called heteroscedasticity. If all of the residuals are equal, or do not fan out, they exhibit homoscedasticity. However, a terminological...
16 KB (2,168 words) - 18:00, 25 November 2023
Bartlett's test, named after Maurice Stevenson Bartlett, is used to test homoscedasticity, that is, if multiple samples are from populations with equal variances...
4 KB (687 words) - 22:21, 26 April 2024
analysis in the presence of heteroscedasticity, which led to his formulation of the autoregressive conditional heteroscedasticity (ARCH) modeling technique...
5 KB (1,154 words) - 04:37, 9 June 2024
Carlos M.; Bera, Anil K. (1980). "Efficient tests for normality, homoscedasticity and serial independence of regression residuals". Economics Letters....
7 KB (901 words) - 07:42, 24 May 2024

Stratified sampling (section Mean and standard error)
should be collectively exhaustive and mutually exclusive: every element in the population must be assigned to one and only one stratum. Then sampling is...
11 KB (1,512 words) - 09:33, 17 December 2024

fourth spread, or H‑spread. It is defined as the difference between the 75th and 25th percentiles of the data. To calculate the IQR, the data set is divided...
10 KB (1,144 words) - 07:55, 10 August 2024

In statistical significance testing, a one-tailed test and a two-tailed test are alternative ways of computing the statistical significance of a parameter...
12 KB (1,759 words) - 11:25, 12 February 2024

descriptive statistics (in the mass noun sense) is the process of using and analysing those statistics. Descriptive statistics is distinguished from...
8 KB (961 words) - 01:30, 17 October 2024
with probability p and value 0 with probability q = 1 − p. The Rademacher distribution, which takes value 1 with probability 1/2 and value −1 with probability...
22 KB (2,609 words) - 12:49, 10 February 2024
Linear regression (section Heteroscedastic models)
including weighted least squares and the use of heteroscedasticity-consistent standard errors can handle heteroscedasticity in a quite general way. Bayesian...
75 KB (10,428 words) - 22:33, 21 December 2024
a test of normality. It was published in 1965 by Samuel Sanford Shapiro and Martin Wilk. The Shapiro–Wilk test tests the null hypothesis that a sample...
7 KB (782 words) - 22:07, 12 December 2024

specific data set, there are four basic combinations of actual data category and assigned category: true positives TP (correct positive assignments), true...
12 KB (1,417 words) - 11:00, 30 October 2024
common measures of central tendency are the arithmetic mean, the median, and the mode. A middle tendency can be calculated for either a finite set of...
13 KB (1,720 words) - 13:56, 19 August 2024
models, typically one found by maximization over the entire parameter space and another found after imposing some constraint, based on the ratio of their...
17 KB (2,098 words) - 09:11, 20 July 2024

gathering and measuring information on targeted variables in an established system, which then enables one to answer relevant questions and evaluate outcomes...
9 KB (992 words) - 06:59, 2 October 2024

Least squares (category Optimization algorithms and methods)
covariance matrix diagonal) may still be unequal (heteroscedasticity). In simpler terms, heteroscedasticity is when the variance of Y i {\displaystyle Y_{i}}...
39 KB (5,662 words) - 21:08, 21 December 2024
Herfindahl index Heston model Heteroscedasticity Heteroscedasticity-consistent standard errors Heteroskedasticity – see Heteroscedasticity Hidden Markov model Hidden...
87 KB (8,285 words) - 04:29, 7 October 2024
correlation coefficient exist, each with their own definition and own range of usability and characteristics. They all assume values in the range from −1...
8 KB (754 words) - 20:58, 28 November 2024
psychology, and political science. Monte Carlo methods have been recognized as one of the most important and influential ideas of the 20th century, and they...
91 KB (10,518 words) - 09:53, 11 December 2024

distributed under the null hypothesis, specifically Pearson's chi-squared test and variants thereof. Pearson's chi-squared test is used to determine whether...
22 KB (2,399 words) - 13:31, 7 August 2024

Polynomial regression (section Definition and example)
regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial...
16 KB (2,426 words) - 05:32, 14 November 2024
used to determine if a data set is well-modeled by a normal distribution and to compute how likely it is for a random variable underlying the data set...
12 KB (1,624 words) - 06:30, 27 August 2024
Multivariate statistics (section Software and tools)
is a subdivision of statistics encompassing the simultaneous observation and analysis of more than one outcome variable, i.e., multivariate random variables...
17 KB (1,859 words) - 21:49, 15 December 2024

In mathematical optimization and decision theory, a loss function or cost function (sometimes also called an error function) is a function that maps an...
21 KB (2,799 words) - 16:21, 20 December 2024
mass, the first moment (normalized by total mass) is the center of mass, and the second moment is the moment of inertia. If the function is a probability...
21 KB (3,066 words) - 18:56, 8 December 2024

normal score, standardized variable and pull in high energy physics. Computing a z-score requires knowledge of the mean and standard deviation of the complete...
15 KB (1,861 words) - 09:24, 17 December 2024