and other applications of multivariate time series analysis, a variance decomposition or forecast error variance decomposition (FEVD) is used to aid in...
3 KB (662 words) - 08:36, 7 June 2022
analysis Variance Variance decomposition of forecast errors Variance gamma process Variance inflation factor Variance-gamma distribution Variance reduction...
87 KB (8,285 words) - 04:29, 7 October 2024
estimate of the variance of the unobserved errors, and is called the mean squared error. Another method to calculate the mean square of error when analyzing...
16 KB (2,168 words) - 18:00, 25 November 2023
Autoregressive integrated moving average (redirect from ARIMA forecasting method)
ARIMA models and regression with ARIMA errors NCSS: includes several procedures for ARIMA fitting and forecasting. Python: the "statsmodels" package includes...
24 KB (3,433 words) - 05:56, 9 October 2024

Principal component analysis (category Matrix decompositions)
proper orthogonal decomposition (POD) in mechanical engineering, singular value decomposition (SVD) of X (invented in the last quarter of the 19th century)...
114 KB (14,369 words) - 17:37, 9 October 2024
Wold decomposition. Kendall shows an example of a decomposition into smooth, seasonal and irregular factors for a set of data containing values of the...
7 KB (839 words) - 13:54, 1 November 2023
Linear regression (redirect from Error variable)
Analysis of variance Blinder–Oaxaca decomposition Censored regression model Cross-sectional regression Curve fitting Empirical Bayes method Errors and residuals...
75 KB (10,420 words) - 11:59, 15 October 2024
Covariance (redirect from Co-variance)
'observation error covariance matrix' is constructed to represent the magnitude of combined observational errors (on the diagonal) and the correlated errors between...
29 KB (4,739 words) - 16:25, 8 October 2024

Time series (redirect from Time Series Forecasting)
series Chirp Decomposition of time series Detrended fluctuation analysis Digital signal processing Distributed lag Estimation theory Forecasting Frequency...
41 KB (4,860 words) - 20:49, 9 October 2024
that the square root of the sample variance is an underestimate. The use of n − 1 instead of n in the formula for the sample variance is known as Bessel's...
18 KB (2,951 words) - 11:35, 10 May 2024

independent variables are not error-free, this is an errors-in-variables model, also outside this scope. Other examples of nonlinear functions include exponential...
10 KB (1,394 words) - 02:15, 28 March 2024
Autoregressive model (redirect from Autoregressive forecasting)
the error term ε t {\displaystyle \varepsilon _{t}} equal to zero (because we forecast Xt to equal its expected value, and the expected value of the unobserved...
34 KB (5,415 words) - 19:28, 16 October 2024
{C}}=(X_{1}-\mu ,\ldots ,X_{n}-\mu )} can be decomposed into the "mean part" and "variance part" by projecting to the direction of u → = ( 1 , … , 1 ) {\displaystyle...
34 KB (5,360 words) - 19:12, 10 August 2024
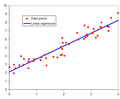
Regression analysis (redirect from History of regression analysis)
the variance of e i {\displaystyle e_{i}} to change across values of X i {\displaystyle X_{i}} . Correlated errors that exist within subsets of the data...
37 KB (5,116 words) - 06:21, 17 October 2024
Prediction interval (category Statistical forecasting)
with known mean 0 but unknown variance σ 2 {\displaystyle \sigma ^{2}} , the sample variance s 2 {\displaystyle s^{2}} of the observations X 1 , … , X...
20 KB (2,853 words) - 06:10, 17 October 2024

Autocorrelation (redirect from List of applications of autocorrelation)
autocorrelation of the errors, which themselves are unobserved, can generally be detected because it produces autocorrelation in the observable residuals. (Errors are...
39 KB (5,807 words) - 01:47, 17 September 2024
Sensitivity analysis (section Variance-based methods)
distributions, and decompose the output variance into parts attributable to input variables and combinations of variables. The sensitivity of the output to...
56 KB (6,939 words) - 19:25, 16 October 2024
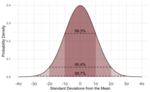
Statistics (redirect from Applications of statistics)
forms of error are recognized: Type I errors (null hypothesis is rejected when it is in fact true, giving a "false positive") and Type II errors (null...
77 KB (8,713 words) - 09:49, 12 October 2024
smoothing method can be estimated by minimizing the sum of squared errors (SSE). The errors are specified as e t = y t − y ^ t ∣ t − 1 {\textstyle e_{t}=y_{t}-{\hat...
27 KB (4,314 words) - 21:07, 8 October 2024
\sigma ^{2}} is the variance of the white noise, θ {\displaystyle \theta } is the characteristic polynomial of the moving average part of the ARMA model,...
19 KB (2,445 words) - 16:29, 1 October 2024
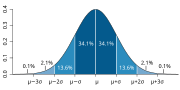
square root of the variance, and hence another measure of dispersion. Symmetry: a property of some distributions in which the portion of the distribution...
47 KB (6,403 words) - 14:52, 16 August 2024

change over time in the parameters of regression models, which can lead to huge forecasting errors and unreliability of the model in general. This issue...
16 KB (1,373 words) - 00:23, 20 March 2024
Linear trend estimation (category Statistical forecasting)
{\displaystyle e} 's are randomly distributed errors. If one can reject the null hypothesis that the errors are non-stationary, then the non-stationary...
15 KB (2,171 words) - 15:26, 17 August 2024
vector autoregression, an extension of VAR models to panel data Variance decomposition For multivariate tests for autocorrelation in the VAR models, see...
21 KB (3,496 words) - 19:54, 16 August 2024
information criterion Bias-variance tradeoff Mean squared error Errors and residuals in statistics Law of total variance Mallows's Cp Model selection...
6 KB (1,025 words) - 20:21, 17 March 2023
Ensemble learning (redirect from Ensembles of classifiers)
outcome and error values exhibit high variance. Fundamentally, an ensemble learning model trains at least two high-bias (weak) and high-variance (diverse)...
52 KB (6,574 words) - 09:39, 19 October 2024
R {\displaystyle R} describes the estimate of the error of the data; if the random errors in the entries of the data vector d {\displaystyle \mathbf {d}...
25 KB (3,897 words) - 21:06, 5 October 2024
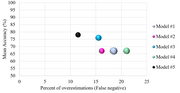
distributed, the mean squared error, root mean squared error or median absolute deviation could be used to summarize the errors. When users apply cross-validation...
42 KB (5,623 words) - 18:40, 25 June 2024
Electricity price forecasting (EPF) is a branch of energy forecasting which focuses on using mathematical, statistical and machine learning models to...
66 KB (7,298 words) - 04:25, 7 October 2024
transpose of row i of the matrix X . {\displaystyle \mathbf {X} .} It is also efficient under the assumption that the errors have finite variance and are...
34 KB (5,374 words) - 18:47, 15 September 2024