Similarity learning is an area of supervised machine learning in artificial intelligence. It is closely related to regression and classification, but...
11 KB (1,526 words) - 18:29, 13 May 2024
the similarity of documents in the vector space model. In machine learning, common kernel functions such as the RBF kernel can be viewed as similarity functions...
17 KB (2,570 words) - 04:35, 12 July 2024
analysis, cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of...
22 KB (3,068 words) - 15:50, 11 July 2024
height of a person, or the future temperature. Similarity learning is an area of supervised machine learning closely related to regression and classification...
134 KB (14,772 words) - 03:33, 8 July 2024
not just by arbitrary descriptors. Deep learning methods have become an accurate way to gauge semantic similarity between two text passages, in which each...
38 KB (4,216 words) - 00:39, 26 March 2024

K-nearest neighbor algorithm Neural networks (Multilayer perceptron) Similarity learning Given a set of N {\displaystyle N} training examples of the form...
22 KB (3,011 words) - 18:41, 25 June 2024
unlabeled data. Within such an approach, a machine learning model tries to find any similarities, differences, patterns, and structure in data by itself...
28 KB (2,467 words) - 14:51, 10 June 2024
www.sisap.org Similarity learning Latent semantic analysis Pei Lee, Laks V. S. Lakshmanan, Jeffrey Xu Yu: On Top-k Structural Similarity Search. ICDE 2012:774-785...
6 KB (766 words) - 18:42, 7 March 2024
Siamese neural network (section Learning)
Systems. 6: 737–744. Chopra, S.; Hadsell, R.; LeCun, Y. (June 2005). "Learning a Similarity Metric Discriminatively, with Application to Face Verification"...
12 KB (1,575 words) - 00:45, 13 April 2024
gradient methods for learning Semantic analysis Similarity learning Sparse dictionary learning Stability (learning theory) Statistical learning theory Statistical...
41 KB (3,580 words) - 16:15, 14 June 2024

Triplet loss (category Machine learning algorithms)
for learning similarity for the purpose of learning embeddings, such as learning to rank, word embeddings, thought vectors, and metric learning. Consider...
7 KB (927 words) - 09:46, 6 July 2024
learning. Factors that can affect transfer include: Context and degree of original learning: how well the learner acquired the knowledge. Similarity:...
12 KB (1,293 words) - 05:38, 9 September 2023
linguistics, lexical similarity is a measure of the degree to which the word sets of two given languages are similar. A lexical similarity of 1 (or 100%) would...
7 KB (583 words) - 01:17, 12 July 2024
Kernel method (category Kernel methods for machine learning)
for vector output Kernel density estimation Representer theorem Similarity learning Cover's theorem "Kernel method". Engati. Retrieved 2023-04-04. Theodoridis...
13 KB (1,668 words) - 12:03, 31 March 2024
Zero-shot learning (ZSL) is a problem setup in deep learning where, at test time, a learner observes samples from classes which were not observed during...
12 KB (1,384 words) - 08:09, 7 June 2024
String metric (redirect from String similarity)
(also known as a string similarity metric or string distance function) is a metric that measures distance ("inverse similarity") between two text strings...
8 KB (527 words) - 23:12, 14 May 2024

research that explores methodological and structural similarities between certain physical systems and learning systems, in particular neural networks. For example...
85 KB (10,301 words) - 07:49, 25 June 2024

Deep learning is the subset of machine learning methods based on neural networks with representation learning. The adjective "deep" refers to the use of...
179 KB (17,806 words) - 08:30, 12 July 2024
Hellinger distance, also a measure of distance between data sets Similarity learning, for other approaches to learn a distance metric from examples. "Reprint...
19 KB (2,684 words) - 09:30, 23 June 2024

Schneider, Stefan; Taylor, Graham W.; Kremer, Stefan C. (2020). "Similarity Learning Networks for Animal Individual Re-Identification - Beyond the Capabilities...
51 KB (5,540 words) - 17:02, 20 June 2024
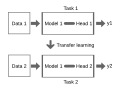
Bozinovski and Ante Fulgosi (1976). "The influence of pattern similarity and transfer learning upon the training of a base perceptron B2." (original in Croatian)...
13 KB (1,359 words) - 07:30, 3 June 2024
Competitive learning is a form of unsupervised learning in artificial neural networks, in which nodes compete for the right to respond to a subset of...
6 KB (774 words) - 14:48, 6 May 2024
of data items and a similarity function. These models learn the embeddings by leveraging statistical techniques and machine learning algorithms. Here are...
10 KB (1,175 words) - 05:59, 2 January 2024
interpolation Neighbor joining Principal component analysis Range search Similarity learning Singular value decomposition Sparse distributed memory Statistical...
27 KB (3,341 words) - 08:02, 26 June 2024
and scholars have drawn similarities between implicit learning and implicit memory. Examples from daily life, like learning how to ride a bicycle or...
28 KB (3,673 words) - 09:47, 13 August 2023
Vector database (category Machine learning)
feature vectors close to each other. Vector databases can be used for similarity search, multi-modal search, recommendations engines, large language models...
19 KB (1,401 words) - 17:58, 9 July 2024

; Evans, Selby H. (March 1970), "Pythagorean distance and the judged similarity of schematic stimuli", Perception & Psychophysics, 7 (2): 103–107, doi:10...
25 KB (3,188 words) - 23:31, 17 March 2024

In machine learning, a neural network (also artificial neural network or neural net, abbreviated ANN or NN) is a model inspired by the structure and function...
163 KB (17,346 words) - 13:00, 3 July 2024

association are contiguity, repetition, attention, pleasure-pain, and similarity. The basic laws were formulated by Aristotle in approximately 300 B.C...
1 KB (91 words) - 06:09, 13 June 2023
Kernel perceptron (category Kernel methods for machine learning)
non-linear classifiers that employ a kernel function to compute the similarity of unseen samples to training samples. The algorithm was invented in 1964...
9 KB (1,175 words) - 22:03, 5 May 2021