In statistics and econometrics, the maximum score estimator is a nonparametric estimator for discrete choice models developed by Charles Manski in 1975...
11 KB (2,033 words) - 22:22, 29 June 2021
Maximum score may refer to: Maximum score estimator, a statistical method developed by Charles Manski in 1975. Maximum score (golf), a format of play in...
279 bytes (73 words) - 14:58, 22 August 2023
^{n}\to \Theta \;} so defined is measurable, then it is called the maximum likelihood estimator. It is generally a function defined over the sample space, i...
68 KB (9,706 words) - 01:34, 1 July 2025
M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood...
22 KB (2,854 words) - 17:15, 5 November 2024
utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation. Suppose an unknown parameter...
22 KB (3,845 words) - 16:15, 22 August 2024
Bassett, Robert; Deride, Julio (2018-01-30). "Maximum a posteriori estimators as a limit of Bayes estimators". Mathematical Programming: 1–16. arXiv:1611...
11 KB (1,725 words) - 05:26, 19 December 2024
three-digit score is based on a theoretical maximum of 300, but this has not been documented by the NBME / FSMB. Previously, a 2 digit score was also provided...
3 KB (281 words) - 11:00, 22 January 2024
hypothesis. Intuitively, if the restricted estimator is near the maximum of the likelihood function, the score should not differ from zero by more than...
11 KB (1,600 words) - 09:50, 2 July 2025
the maximum score estimator, have been proposed. Estimation of such models is usually done via parametric, semi-parametric and non-parametric maximum likelihood...
47 KB (6,349 words) - 19:27, 23 June 2025

The Kaplan–Meier estimator, also known as the product limit estimator, is a non-parametric statistic used to estimate the survival function from lifetime...
27 KB (4,445 words) - 12:14, 1 July 2025
minimum-variance unbiased estimator (MVUE) or uniformly minimum-variance unbiased estimator (UMVUE) is an unbiased estimator that has lower variance than...
7 KB (1,109 words) - 21:36, 14 April 2025
{\displaystyle f(y;\theta )} , and we wish to calculate the maximum likelihood estimator (M.L.E.) θ ∗ {\displaystyle \theta ^{*}} of θ {\displaystyle...
3 KB (512 words) - 10:36, 28 May 2025
on subjects that have the same value of the balancing score, can serve as an unbiased estimator of the average treatment effect: E [ r 1 ] − E [ r 0 ]...
19 KB (2,470 words) - 22:25, 13 March 2025
In statistics, the bias of an estimator (or bias function) is the difference between this estimator's expected value and the true value of the parameter...
34 KB (5,367 words) - 15:44, 15 April 2025
the estimate according to the maximum likelihood estimator is difficult; e.g. the Cochran–Mantel–Haenzel test is a score test. Chow test Sequential probability...
17 KB (2,232 words) - 02:25, 26 May 2025
MANCOVA Manhattan plot Mann–Whitney U MANOVA Mantel test MAP estimator – redirects to Maximum a posteriori estimation Marchenko–Pastur distribution Marcinkiewicz–Zygmund...
87 KB (8,280 words) - 23:04, 12 March 2025
Average absolute deviation (redirect from Maximum absolute deviation)
{\displaystyle D_{\text{med}}=E|X-{\text{median}}|} This is the maximum likelihood estimator of the scale parameter b {\displaystyle b} of the Laplace distribution...
13 KB (1,674 words) - 05:19, 18 June 2025
Bootstrapping is a procedure for estimating the distribution of an estimator by resampling (often with replacement) one's data or a model estimated from...
69 KB (9,407 words) - 17:54, 23 May 2025
Robust statistics (redirect from Robust estimator)
function. MLE are therefore a special case of M-estimators (hence the name: "Maximum likelihood type" estimators). Minimizing ∑ i = 1 n ρ ( x i ) {\textstyle...
46 KB (6,376 words) - 01:05, 20 June 2025
represents a maximum likelihood estimator, nor are any as asymptotically efficient as the maximum likelihood estimator; however, the maximum likelihood...
9 KB (1,192 words) - 19:10, 26 June 2023
Rao–Blackwell theorem (redirect from Rao-Blackwell estimator)
that characterizes the transformation of an arbitrarily crude estimator into an estimator that is optimal by the mean-squared-error criterion or any of...
13 KB (2,174 words) - 20:32, 19 June 2025

Median (redirect from Median unbiased estimator)
^{*})^{2}} to obtain the mean; the strong justification of this estimator by reference to maximum likelihood estimation based on a normal distribution means...
63 KB (7,987 words) - 23:47, 14 June 2025
The ratio estimator is a statistical estimator for the ratio of means of two random variables. Ratio estimates are biased and corrections must be made...
22 KB (4,015 words) - 19:09, 2 May 2025

75th percentile, so IQR = Q3 − Q1. The IQR is an example of a trimmed estimator, defined as the 25% trimmed range, which enhances the accuracy of dataset...
10 KB (1,144 words) - 14:51, 27 February 2025
Estimation theory Estimator Bayes estimator Maximum likelihood Trimmed estimator M-estimator Minimum-variance unbiased estimator Consistent estimator Efficiency...
9 KB (753 words) - 12:06, 11 April 2024
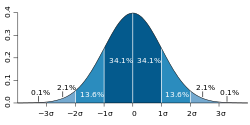
sample mean is a simple estimator with many desirable properties (unbiased, efficient, maximum likelihood), there is no single estimator for the standard deviation...
59 KB (8,235 words) - 23:08, 17 June 2025

the location of the maximum of the function Sn. This section presents two examples of calculating the maximum spacing estimator. Suppose two values x(1)...
26 KB (3,328 words) - 19:23, 2 March 2025
normal, minimum-distance estimators are generally not statistically efficient when compared to maximum likelihood estimators, because they omit the Jacobian...
6 KB (696 words) - 23:51, 22 June 2024

In statistics, the standard score or z-score is the number of standard deviations by which the value of a raw score (i.e., an observed value or data point)...
16 KB (1,936 words) - 16:39, 24 May 2025
defined by the stationary point of the score function serve as estimating equations for the maximum likelihood estimator. s n ( θ ) = 0 {\displaystyle s_{n}(\theta...
64 KB (8,546 words) - 13:13, 3 March 2025