
encoding and cyphering systems, such as Bacon's cipher, Braille, international maritime signal flags, and the 4-digit encoding of Chinese characters for...
32 KB (3,860 words) - 10:39, 1 November 2024
character encoding via XML declaration, as follows: <?xml version="1.0" encoding="utf-8"?> With this second approach, because the character encoding cannot...
24 KB (2,460 words) - 20:03, 12 October 2024
URL encoding, officially known as percent-encoding, is a method to encode arbitrary data in a uniform resource identifier (URI) using only the US-ASCII...
18 KB (1,689 words) - 21:42, 1 November 2024
published in 1980. Two encoding schemes existed for GB 2312: a one-or-two byte 8-bit EUC-CN encoding commonly used, and a 7-bit encoding called HZ for usenet...
8 KB (956 words) - 20:37, 7 October 2024
variants of BCD encode the characters '0' through '9' as the corresponding binary values. Technically, binary-coded decimal describes the encoding of decimal...
25 KB (1,884 words) - 22:22, 21 May 2024
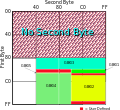
2312-80 in its usual encoding, GBK/1 being the non-hanzi region and GBK/2 the hanzi region. GB 2312, or more properly the EUC-CN encoding thereof, takes a...
14 KB (1,466 words) - 05:33, 1 March 2024

left-to-right scripts when discussing encoding issues. Libraries cooperated on encoding standards for JACKPHY characters in the early 1980s. According to Ken...
8 KB (883 words) - 17:27, 3 November 2024
A double-byte character set (DBCS) is a character encoding in which either all characters (including control characters) are encoded in two bytes, or merely...
5 KB (626 words) - 13:42, 7 October 2024

Japanese language and computers (redirect from Japanese character encoding)
supports the required character. Unicode was intended to solve all encoding problems over all languages. The UTF-8 encoding used to encode Unicode in web pages...
13 KB (1,626 words) - 02:56, 10 September 2024
UTF-8 (redirect from UTF-8 encoding)
stored in UTF-8. UTF-8 is capable of encoding all 1,112,064 valid Unicode scalar values using a variable-width encoding of one to four one-byte (8-bit) code...
47 KB (5,002 words) - 20:34, 3 November 2024
A variable-width encoding is a type of character encoding scheme in which codes of differing lengths are used to encode a character set (a repertoire of...
10 KB (1,556 words) - 13:41, 7 October 2024
encoding is encoding of data in plain text. More precisely, it is an encoding of binary data in a sequence of printable characters. These encodings are...
22 KB (1,374 words) - 17:23, 29 October 2024
Unicode and HTML (section Character encoding)
the document's characters are encoded as a sequence of bit octets (bytes) according to a particular character encoding. This encoding may either be a...
22 KB (2,590 words) - 21:13, 10 October 2024

Mojibake (redirect from Broken character)
one encoding, when the same binary code constitutes one symbol in the other encoding. This is either because of differing constant length encoding (as...
60 KB (5,992 words) - 20:13, 5 November 2024

Windows-1252 (section Related encodings)
Windows-1252 or CP-1252 (Windows code page 1252) is a legacy single-byte character encoding that is used by default (as the "ANSI code page") in Microsoft Windows...
47 KB (2,056 words) - 16:00, 2 November 2024

Two examples of usual encodings are ASCII and the UTF-8 encoding for Unicode. While most character encodings map characters to numbers and/or bit sequences...
17 KB (2,022 words) - 03:35, 2 November 2024
Byte order mark (section Byte-order marks by encoding)
and 32-bit encodings; the fact that the text stream's encoding is Unicode, to a high level of confidence; which Unicode character encoding is used. BOM...
15 KB (1,911 words) - 17:50, 12 August 2024
Base64 (redirect from Base64 (encoding scheme))
binary-to-text encoding schemes that transforms binary data into a sequence of printable characters, limited to a set of 64 unique characters. More specifically...
39 KB (3,747 words) - 21:32, 5 November 2024

ASCII (redirect from ASCII (character encoding))
acronym for American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text...
109 KB (8,087 words) - 17:53, 8 November 2024
Mac OS Roman (redirect from Mac-Roman encoding)
Mac OS Roman is a character encoding created by Apple Computer, Inc. for use by Macintosh computers. It is suitable for representing text in English and...
22 KB (363 words) - 21:56, 9 August 2024
26 characters from А (0xE1) in KOI8-R are А, Б, Ц, Д, Е, Ф, Г, Х, И, Й, К, Л, М, Н, О, П, Я, Р, С, Т, У, Ж, В, Ь, Ы, З. The original KOI encoding (1967)...
14 KB (1,233 words) - 20:59, 20 October 2024
The HZ character encoding is an encoding of GB 2312 that was formerly commonly used in email and USENET postings. It was designed in 1989 by Fung Fung...
6 KB (553 words) - 05:31, 1 March 2024
Shift JIS (redirect from SJIS (character encoding))
single-byte encoding JIS X 0201:1997, that uses unassigned code points in JIS X 0201 to encode the double-byte JIS X 0208:1997 character set. The lead...
23 KB (2,653 words) - 12:27, 1 November 2024

Plain text (section Character encodings)
correctly interpreted via the character encoding in effect. For example, a file or string consisting of "hello" (in any encoding), following by 4 bytes that...
12 KB (1,670 words) - 02:09, 21 October 2024

Extended ASCII (redirect from Extended character)
extended ASCII encoding that applies to it. Applying the wrong encoding causes irrational substitution of many or all extended characters in the text. Software...
15 KB (2,027 words) - 23:39, 21 June 2024
32-bit data paths for character data. This has led to character encoding systems such as UTF-8 that can use multiple bytes to encode a value that is too...
10 KB (1,182 words) - 17:06, 9 September 2023
Unicode (redirect from Script Encoding Initiative)
such encoding in high-level coded software. Punycode, another encoding form, enables the encoding of Unicode strings into the limited character set supported...
106 KB (11,167 words) - 06:49, 8 November 2024
(effectively) the next popular encoding. Big5 is another popular non-UTF encoding meant for traditional Chinese characters (though GB 18030 works for those...
15 KB (1,608 words) - 12:57, 21 October 2024
JSON (section Character encoding)
constrain the character encoding of the Unicode characters in a JSON text, the vast majority of implementations assume UTF-8 encoding; for interoperability...
46 KB (4,866 words) - 17:21, 4 November 2024