
Character encoding is the process of assigning numbers to graphical characters, especially the written characters of human language, allowing them to...
32 KB (3,869 words) - 13:24, 30 July 2024
character encoding via XML declaration, as follows: <?xml version="1.0" encoding="utf-8"?> With this second approach, because the character encoding cannot...
24 KB (2,460 words) - 13:45, 12 August 2024
URL encoding, officially known as percent-encoding, is a method to encode arbitrary data in a uniform resource identifier (URI) using only the US-ASCII...
19 KB (1,735 words) - 04:37, 12 August 2024
variants of BCD encode the characters '0' through '9' as the corresponding binary values. Technically, binary-coded decimal describes the encoding of decimal...
25 KB (1,884 words) - 22:22, 21 May 2024
published in 1980. Two encoding schemes existed for GB 2312: a one-or-two byte 8-bit EUC-CN encoding commonly used, and a 7-bit encoding called HZ for usenet...
8 KB (956 words) - 04:28, 29 February 2024
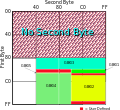
2312-80 in its usual encoding, GBK/1 being the non-hanzi region and GBK/2 the hanzi region. GB 2312, or more properly the EUC-CN encoding thereof, takes a...
14 KB (1,466 words) - 05:33, 1 March 2024
A variable-width encoding is a type of character encoding scheme in which codes of differing lengths are used to encode a character set (a repertoire of...
10 KB (1,550 words) - 18:09, 28 January 2024
UTF-8 (redirect from UTF-8 encoding)
UTF-8 is a variable-length character encoding standard used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode...
100 KB (8,707 words) - 15:23, 10 August 2024

left-to-right scripts when discussing encoding issues. Libraries cooperated on encoding standards for JACKPHY characters in the early 1980s. According to Ken...
8 KB (868 words) - 04:11, 28 August 2024
encoding is encoding of data in plain text. More precisely, it is an encoding of binary data in a sequence of printable characters. These encodings are...
22 KB (1,374 words) - 08:17, 13 August 2024
A double-byte character set (DBCS) is a character encoding in which either all characters (including control characters) are encoded in two bytes, or merely...
5 KB (620 words) - 17:56, 23 July 2024

Japanese language and computers (redirect from Japanese character encoding)
supports the required character. Unicode was intended to solve all encoding problems over all languages. The UTF-8 encoding used to encode Unicode in web pages...
13 KB (1,622 words) - 18:14, 29 March 2024
Byte order mark (section Byte-order marks by encoding)
and 32-bit encodings; the fact that the text stream's encoding is Unicode, to a high level of confidence; which Unicode character encoding is used. BOM...
15 KB (1,911 words) - 17:50, 12 August 2024
Shift JIS (redirect from SJIS (character encoding))
single-byte encoding JIS X 0201:1997, that uses unassigned code points in JIS X 0201 to encode the double-byte JIS X 0208:1997 character set. The lead...
22 KB (2,605 words) - 19:47, 18 July 2024

Two examples of usual encodings are ASCII and the UTF-8 encoding for Unicode. While most character encodings map characters to numbers and/or bit sequences...
17 KB (2,025 words) - 23:31, 5 March 2024
Base64 (redirect from Base64 (encoding scheme))
binary-to-text encoding schemes that transforms binary data into a sequence of printable characters, limited to a set of 64 unique characters. More specifically...
39 KB (3,772 words) - 21:16, 29 August 2024

Mojibake (redirect from Broken character)
one encoding, when the same binary code constitutes one symbol in the other encoding. This is either because of differing constant length encoding (as...
60 KB (5,985 words) - 08:26, 25 August 2024
Unicode and HTML (section Character encoding)
the document's characters are encoded as a sequence of bit octets (bytes) according to a particular character encoding. This encoding may either be a...
22 KB (2,591 words) - 19:24, 28 June 2024

Windows-1252 (section Related encodings)
Windows-1252 or CP-1252 (Windows code page 1252) is a legacy single-byte character encoding that is used by default (as the "ANSI code page") in Microsoft Windows...
46 KB (2,041 words) - 20:29, 25 August 2024

Plain text (section Character encodings)
correctly interpreted via the character encoding in effect. For example, a file or string consisting of "hello" (in any encoding), following by 4 bytes that...
12 KB (1,658 words) - 20:15, 5 July 2024
JSON (section Character encoding)
constrain the character encoding of the Unicode characters in a JSON text, the vast majority of implementations assume UTF-8 encoding; for interoperability...
45 KB (4,858 words) - 22:55, 26 August 2024

ASCII (redirect from ASCII (character encoding))
acronym for American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text...
108 KB (8,064 words) - 14:08, 25 August 2024
GSM 03.38 (redirect from SMS character set)
each national character encoded in this shifted table), or an unspecified proprietary 8-bit encoding, or the use of the UCS-2 encoding (see below). Note...
137 KB (2,051 words) - 15:46, 26 April 2024
or Six-Bit Transmission Code, was, for a few years, one of the three character sets used by IBM for Binary Synchronous Communications. Transmission using...
12 KB (199 words) - 13:16, 1 March 2023
Private Use Areas (redirect from Private use character)
to directly encode alternate forms, ligatures, or base-character-plus-diacritic combinations (such as the TUNE scheme). Emoji is an encoding for picture...
28 KB (2,994 words) - 01:55, 26 August 2024

Extended ASCII (redirect from Extended character)
extended ASCII encoding that applies to it. Applying the wrong encoding causes irrational substitution of many or all extended characters in the text. Software...
15 KB (2,027 words) - 23:39, 21 June 2024
All Character Encoding (TACE16) is a scheme for encoding the Tamil script in the Private Use Area of Unicode, implementing a syllabary-based character model...
14 KB (1,738 words) - 13:06, 18 August 2024
Code point (category Character encoding)
commonly used in character encoding, where a code point is a numerical value that maps to a specific character. In character encoding code points usually...
8 KB (908 words) - 04:48, 18 June 2024
26 characters from А (0xE1) in KOI8-R are А, Б, Ц, Д, Е, Ф, Г, Х, И, Й, К, Л, М, Н, О, П, Я, Р, С, Т, У, Ж, В, Ь, Ы, З. The original KOI encoding (1967)...
14 KB (1,233 words) - 01:54, 26 August 2024